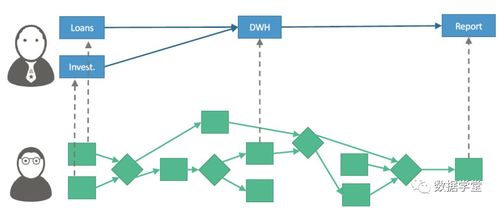
數據血緣關系(Data Lineage)是數據治理中的關鍵概念,它描述了數據從源頭到最終使用的完整流轉路徑,包括數據的來源、轉換過程、依賴關系以及最終流向。在當今數據驅動的業務環境中,數據血緣關系解析已成為企業確保數據質量、合規性和可追溯性的核心技術。
一、數據血緣關系的核心價值
- 數據可追溯性:能夠快速定位數據問題根源,例如在數據報表出現異常時,通過血緣關系追溯至原始數據源或中間處理環節。
- 影響分析:當數據源或處理邏輯變更時,可準確評估對下游系統的影響范圍。
- 合規與審計:滿足GDPR、數據安全法等法規要求,提供完整的數據生命周期記錄。
- 數據資產管理:幫助企業理解數據資產的價值流轉,優化數據架構。
二、數據血緣關系的技術實現方式
- 靜態解析:通過分析SQL腳本、ETL工具配置文件、數據建模工具元數據等,提取表級和字段級的血緣關系。
- 動態追蹤:在數據流水線執行過程中,通過埋點技術實時捕獲數據流轉信息。
- 機器學習輔助:利用自然語言處理技術解析數據文檔,或通過圖算法自動發現潛在的數據關聯。
三、典型應用場景
- 數據倉庫與數據湖:在數倉建設中,血緣關系可清晰展示數據從ODS到DW再到DM層的加工過程。
- 數據遷移項目:確保遷移過程中數據邏輯的完整性和一致性。
- 數據質量管控:建立數據質量問題的快速定位和修復機制。
- 數據安全治理:實現敏感數據的全程監控與權限管控。
四、實踐建議
- 工具選型:根據企業數據架構選擇適合的血緣分析工具,如開源方案(OpenLineage)、商業工具或自研平臺。
- 標準化建設:建立統一的數據命名規范和處理流程,便于自動化采集血緣信息。
- 漸進式實施:從關鍵業務系統開始,逐步擴大覆蓋范圍,避免一次性全面鋪開帶來的實施難度。
- 組織協同:需要數據工程師、分析師和業務人員共同參與,確保血緣信息的準確性和實用性。
五、未來發展趨勢
隨著數據 Mesh、Data Fabric 等新架構的興起,數據血緣關系解析將向更智能化、實時化和自動化的方向發展。同時,與數據目錄、數據質量等工具的深度集成,將為企業提供更完整的數據治理解決方案。
數據血緣關系解析不僅是技術實現,更是組織數據文化的重要組成部分。通過系統化的血緣關系管理,企業能夠真正實現數據的可知、可信、可控,為數字化轉型奠定堅實基礎。









